Python是一门编程语言,一种提高效率的工具,也是一种认知世界的思维方法。不论你现在或者将来从事什么工作,都会用到编程,至少你要具备编程思维。
我们把python学习分为几个阶段,基础语法、数据爬虫、数据分析和办公自动化,这几个阶段让你明确Python学习的方向,知道如何将python和自己的工作发展结合起来。
Print()函数
print()函数的结构,第一部分是print函数名称;第二部分是print后面的括号里的信息,需要注意这里的括号一定是英文输入。这个函数在计算指令中的整体意思就是把括号中的信息帮我打印出来看看。
在print()函数中,不只是字符串才需要引号,数字也可以,不过一旦数字加上引号,这个数字也被当做是字符串在打印。
如果print()函数括号中放入的是数字,或者是数字运算,比如10+20,那么打印出来的内容会是30,因为计算机可以直接处理数学运算,不需要引号。
最常犯的错误就是中英文标点的混用,导致代码出错,这种错误非常隐蔽,很多人都踩过这个坑。很多同学说为什么不能用中文标点,我只能说因为Python语言也是外国人发明的(编程语言几乎都是老外发明的),所以标点符号都是【英文】,计算机也只会识别英文符号,中文就会报错。在今后的python代码运行中最常见的报错提示就是【syntaxError:invalid syntax】(语法错误:无效语法)。
认识转义字符
转义字符是很多程序语言、数据格式和通信协议的形式文法的一部分。表示常见的那些不能显示的字符,如\r(回车)、\b(退格)等等。
\n在转义字符中的意义是换行,将当前位置移到下一行开头。
现在我们开始使用\n转义字符来实现至尊宝台词的自动换行,代码可以这样写:
print(‘曾经有一份真诚的爱情摆在我的面前,\n但是我没有珍惜,等到了失去的时候才后悔莫及,\n尘世间最痛苦的事莫过于此。\n如果可以给我一个机会再来一次的话,\n我会跟那个女孩子说我爱她,\n如果非要把这份爱加上一个期限,\n我希望是一万年!’)
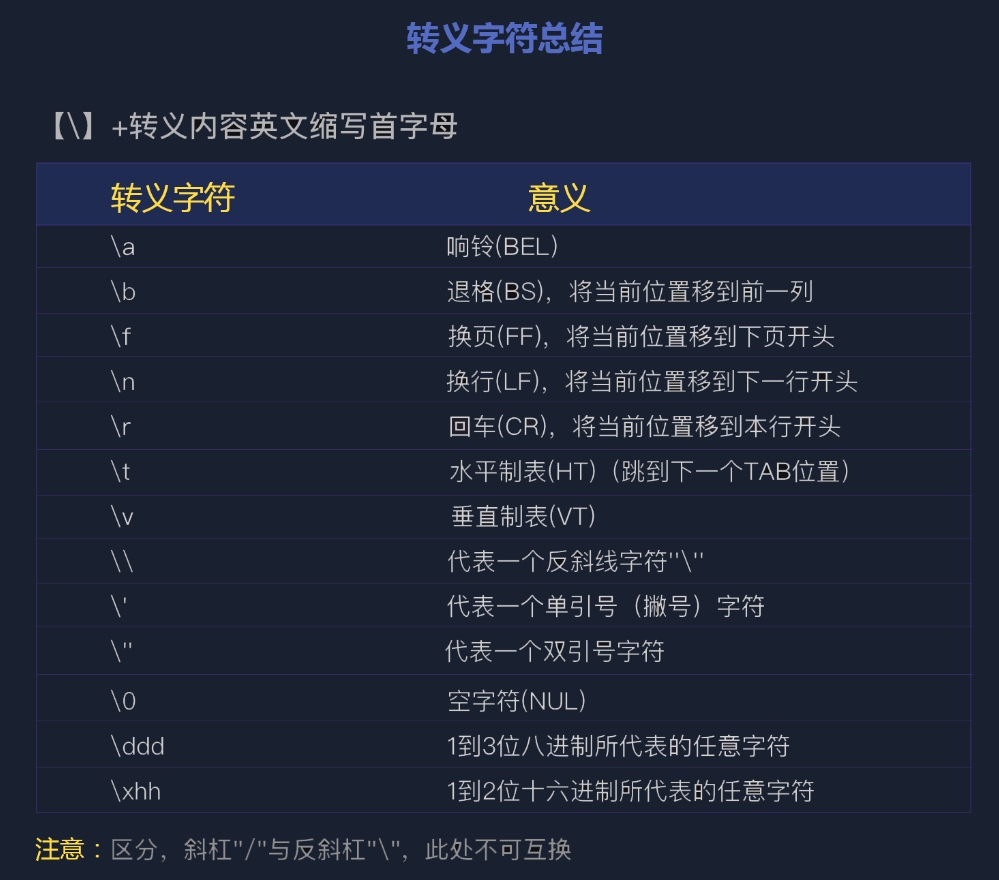
转义字符在编程语言中是不可缺少的,如果你在一对双引号里面,还想要使用双引号,只能使用转义字符了。
变量和赋值
变量命名不能随心所欲,学会规范命名变量是一个程序猿的基本功。
一般情况下,变量命名要遵循以下规则:

如果变量信息是年龄就用age,如果变量信息是名字就用name,如果变量信息是价格就用price,如果变量信息是手机号则应该叫做Phonenumber。
在代码世界中,赋值符号=不是数学运算意义上的左边等于右边,而是表示赋值动作:把右边的数据信息传送到左边。
如果要表示左右完全相等要用运算符==,单等号和双等号在计算机看来差别很大,千万不要混淆。
使用print()函数,变量的值总是等于最后一次赋给它的内容。
数据类型
在Python的基础语法中,最常用的数据类型有三种——字符串(str)、整数(int)和浮点数(float) 。
字符串英文string,简写str。字符串最明显的识别方式就是它的外面要有【引号】,这是字符串最明显的特征。
引号就是字符串数据的身份,只要是被单/双/三引号包括起来的内容,不论这个内容是中文、英文还是数字都表示是字符串类型。
常见数据类型中的第二种:代码界的独行侠——整数。
整数再熟悉不过了,小学阶段就知道了,整数包括正整数、负整数和零,英文为integer,简写做int
因为整数是个“独行侠”,所以它很难跟其他的数据类型合群。如果在print()函数中整数混入中文、英文,电脑就会报错,就像两个仇人相遇,必然要怒目相向。
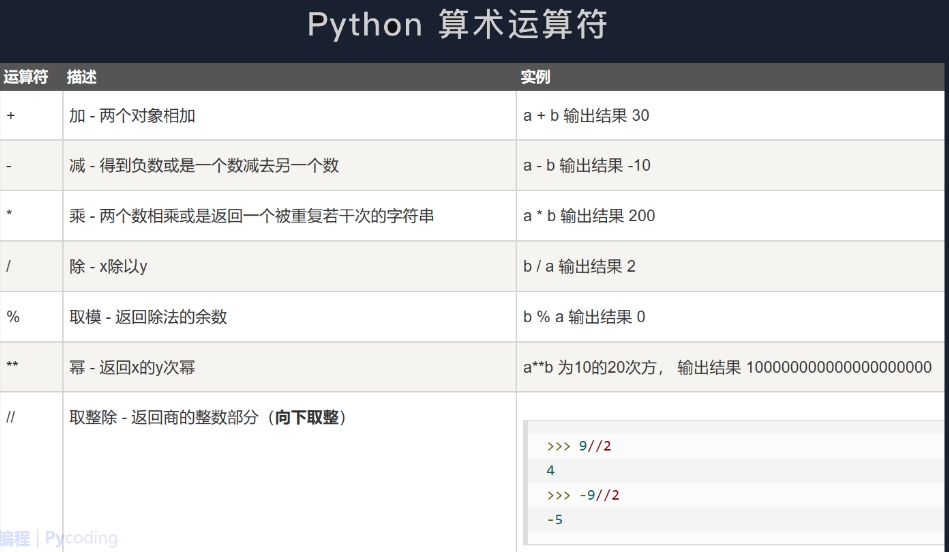
用print()函数进行整数运算,当一个表达式中出现多个操作符时,求值的顺序依赖于优先级规则。Python运算优先级有口诀:

浮点数可以简单理解为带小数点的数字,就是浮点数。编程语言是十分严谨的,整数运算和浮点运算是不同的。
浮点数的英文名是float,在print()函数中打印浮点型数据,要这样写代码print(float(2))。
Python在进行浮点数运算时,会先把像0.02和0.39转化成二进制数才能计算,这里就不再展开了。【注:二进制数由0和1表示,逢二进一】
大家只需要知道浮点型数字不能简单理解为小数运算,要先把十进制数字转换成二进制,相加后后再将二进制结果转成十进制小数,这样计算后的结果就会有偏差。
数据拼接
很多时候数据都是存放在不同的变量当中的,分散在代码的各个角落,要把他们一起打印出来就要懂得——数据拼接。
我们知道以上变量代表的都是字符串数据,要把它们拼接在一起就直接用【+】符号就可以了。
有没有什么方法可以快速查出某个变量是什么数据类型?这就需要一个新的函数type()来解读了。
type()函数
type()函数使用也很简单:只需把查询的内容放在括号里,然后通过print()函数打印出来就行了,代码是这样的print(type(放入需要查询的数据或变量))。
type()函数作用是返回某个对象的数据类型。
type()函数不能直接打印结果,它只是负责查询的。
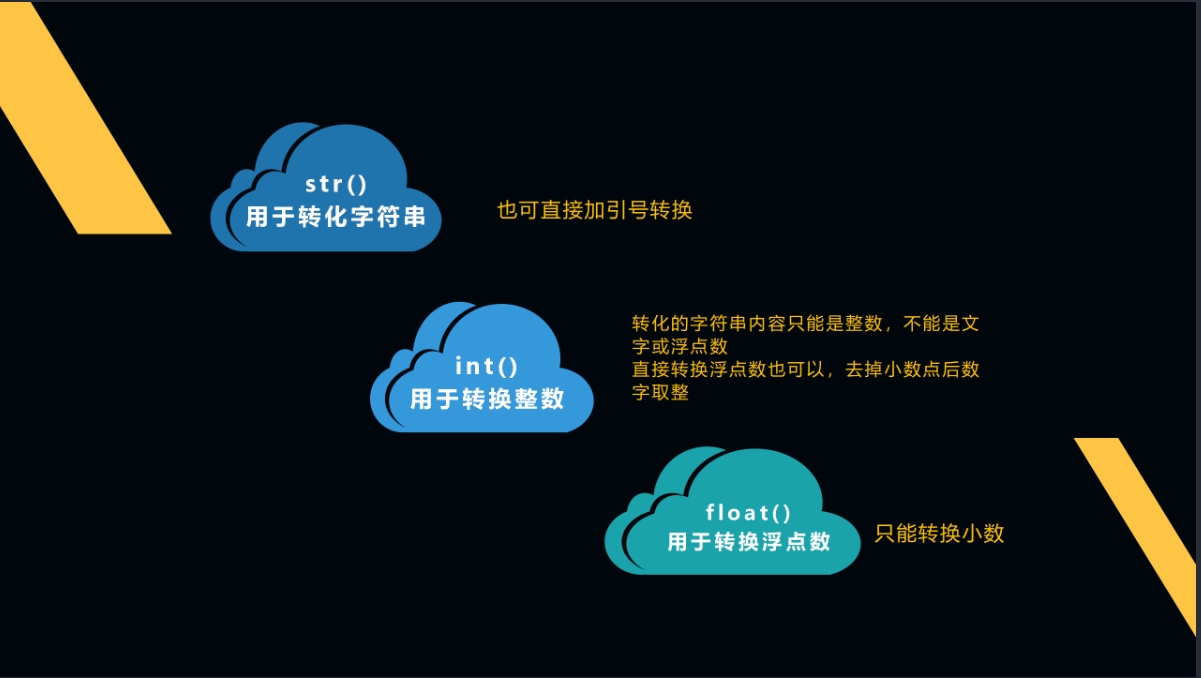
不论数据是中文、数字、标点,str()函数都能将数据转换成其字符串类型,也可以理解成在str()函数的帮助下,数据就会被加上引号变成字符串。
int()函数不能把中文、浮点数类型的字符串或者标点符号转换成整数,字符串内容是整数的数据,才能被int()强制转换,其他类型都会报错。
字符串内容是浮点数类型的不能使用int()函数转换,但浮点数是可以被int()函数转换的。int()函数会直接取整,跟小数四舍五入的处理方法不同。
跟str()和int()函数应用一样,float()函数也是将需要转换的数据放在括号里。
条件判断
Python条件判断定义: 条件语句是一种根据条件执行不同代码的语句,如果条件满足则执行一段代码,否则执行其他代码。可将条件语句认为是有点像起因和结果。
条件判断语句共有三种表现形式:分别是单项判断、双向判断和多向判断。
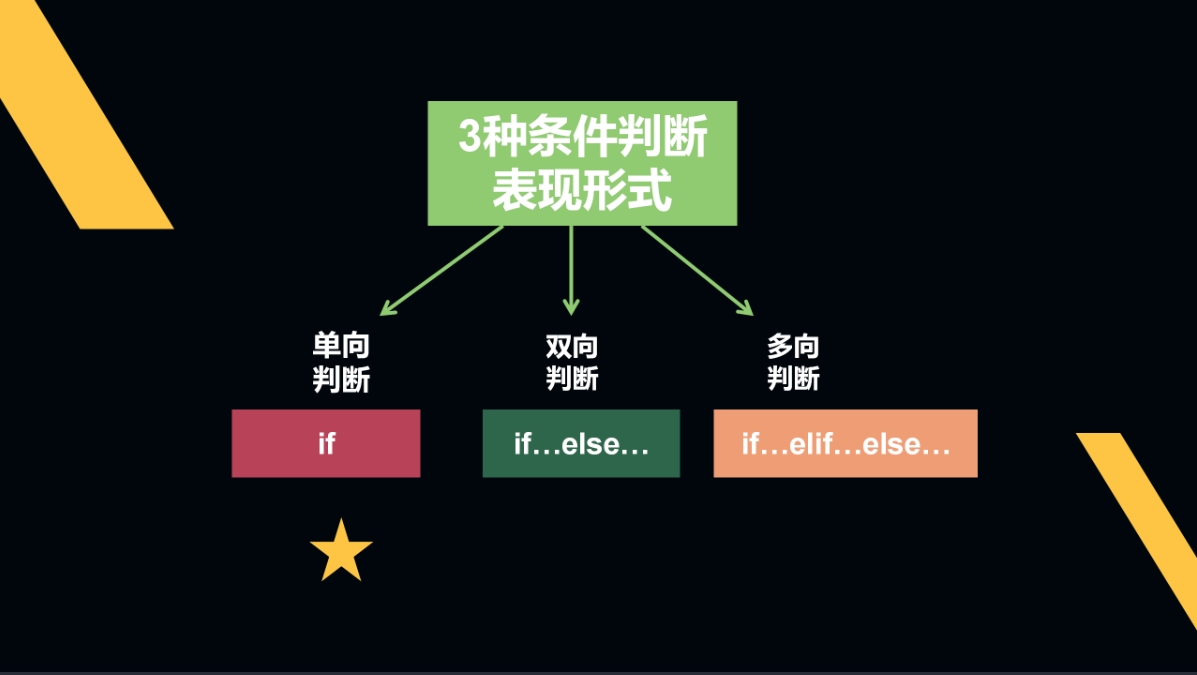
先来讲最简单的单向判断:if。
单向判断:if
if语句的单向判断逻辑,我们可以这样归纳:

在条件判断代码中的冒号后,下一行内容的前面,会空几个格,空格的学名叫缩进,在这里空4个空格。
注意:代码的缩进为一个tab键,或者四个空格(tab键和空格不要混用),格式不对代码就会报错。
在if条件语言中,缩进不需要我们手动按空格键。当你用英文输入法打:后按回车,会自动实现下一行代码,向右缩进的功能。
冒号是条件判断语句的一个特点,一定不要忘记,Python代码缩进主要是用来明确条件执行的逻辑及先后层级的。
if就像是一个小组长,冒号后的内容都是他的成员,当组长if提出一个条件指令时,他下面的成员就要严格照办。
if条件和print命令应该是上下级关系。
if条件赋值
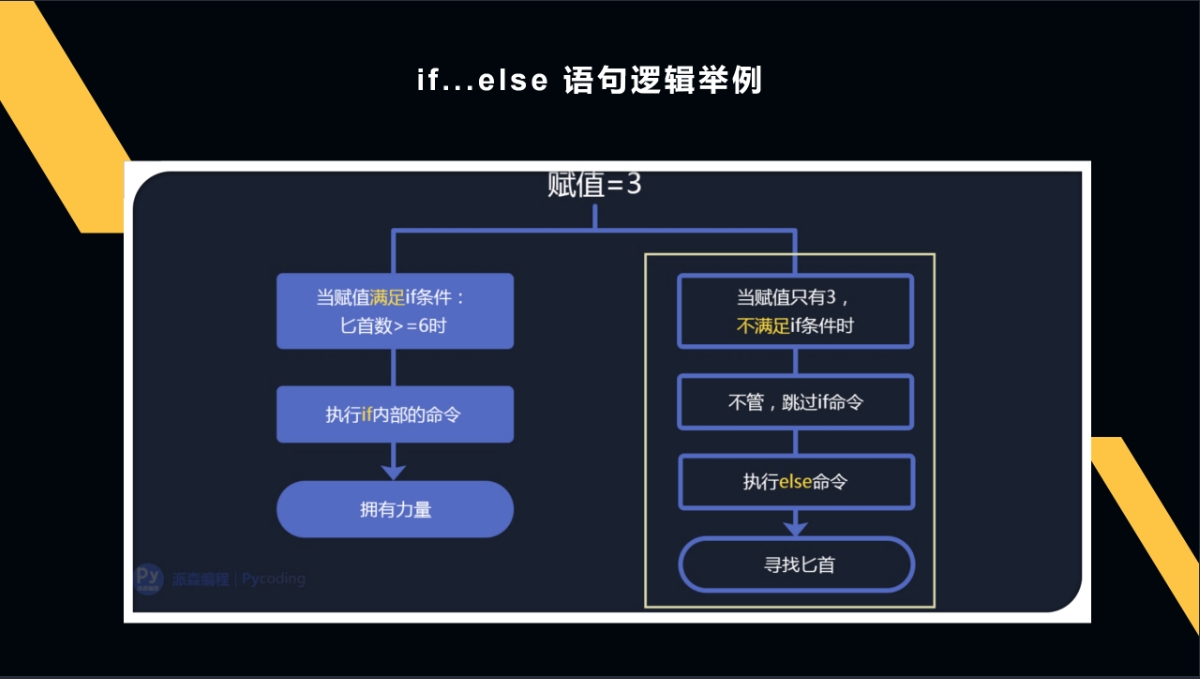
当第一行变量的赋值满足if的条件时,Python的逻辑就会执行if条件下的命令:如果不满足,就无法执行if条件下的命令,会自动跳过执行下一行命令,代码是自上而下运行的。
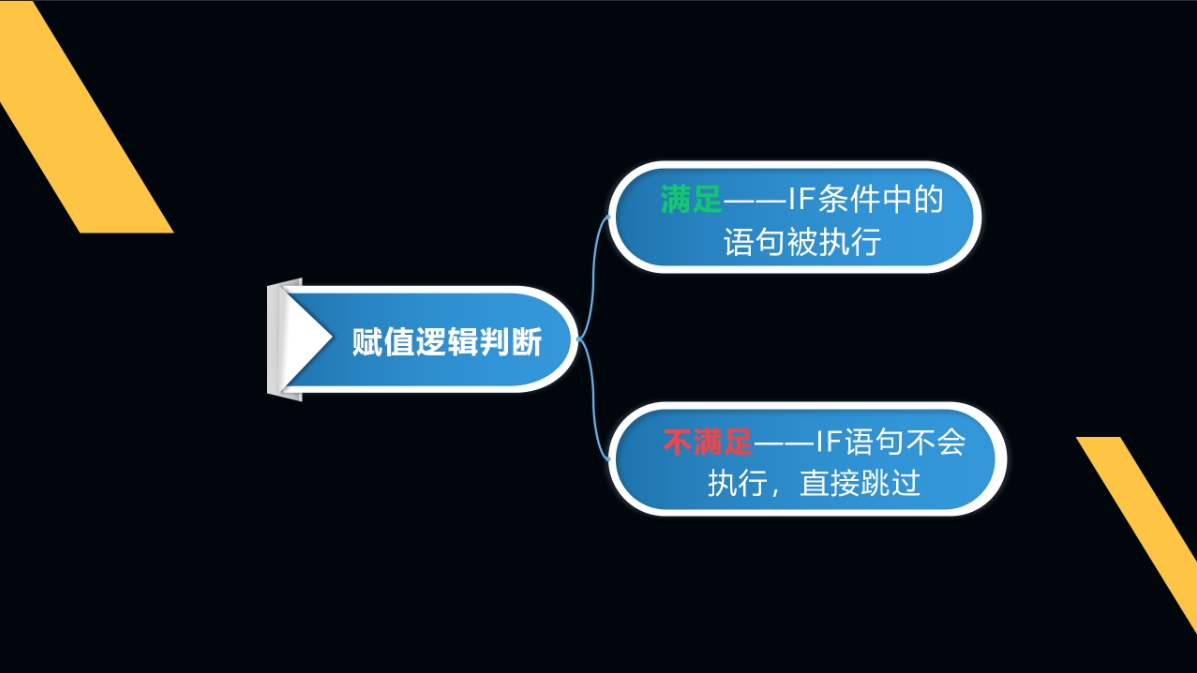
双向判断:if…else…
在双向判断语句里,if…else…是同一层级的,它们都是顶格的,没有缩进,而两个print()是它们的下级。
如果else前出现空格,就会出现报错提示【SyntaxError: invalid syntax】(语法错误:无效语法)。
正确语法下if和else运行的原理:if和else相当于是两个组长,各自带队,他们的级别是一样的。
如果这件事满足if条件就让if去完成,如果不满足就执行else其他条件,互不干扰,分工明确。

多向判断:if…elif…else…
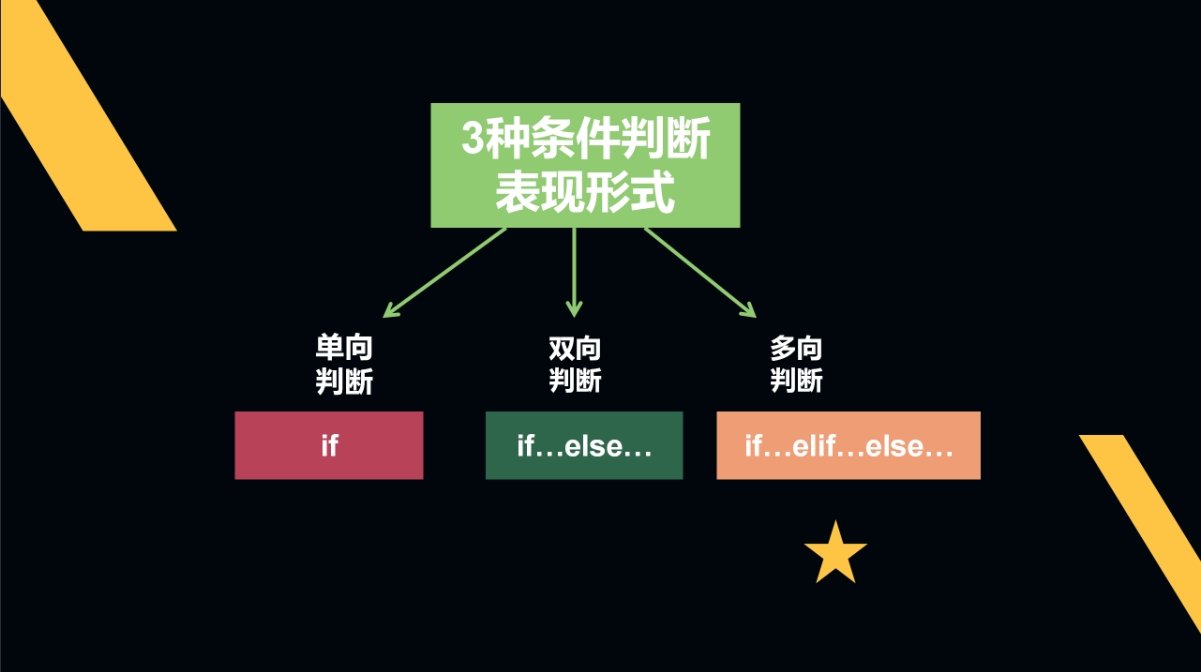
多向判断命令:if…elif…else…用于判断条件达到3个或3个以上。
多向判断的命令逻辑:如果if的条件不满足,就按顺序看是否满足elif的条件,如果不满足elif的条件,就执行else的命令。
当判断的条件超过3个时,中间新增的条件都可以使用elif,如下图所示。
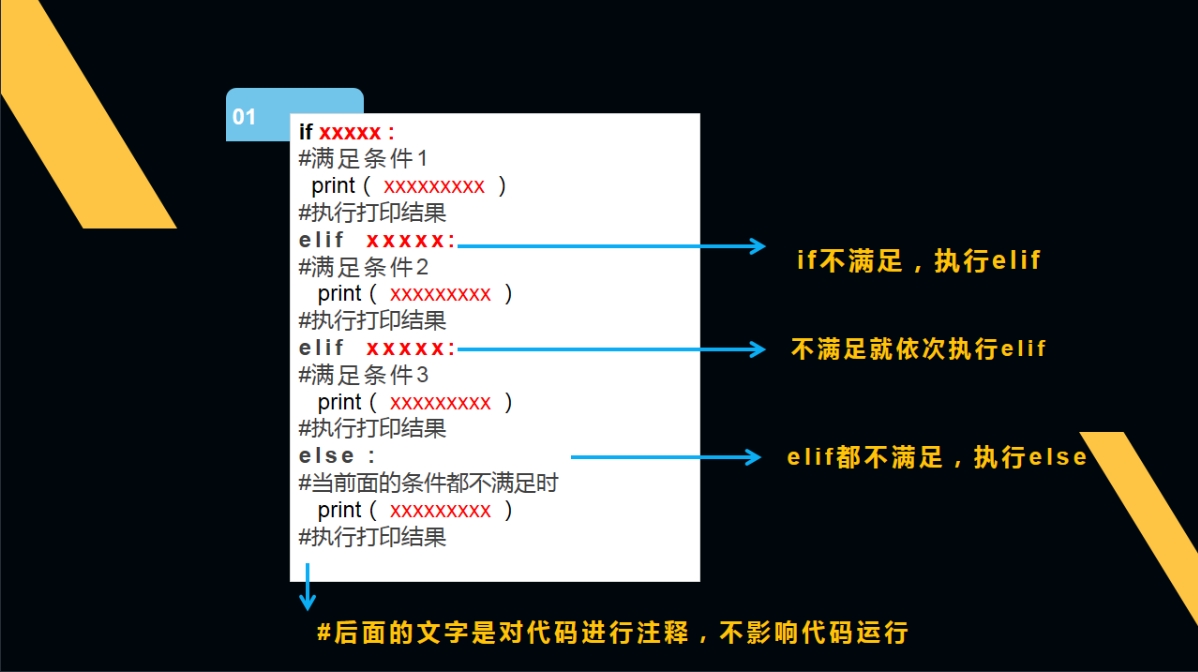
第一行代码为变量赋值,后面的条件会逐个判断一遍,直到满足条件为止。
elif语句一定要跟在if之后,虽然它们之间是平级的,但有个先来后到。elif已经带有其他条件的意思,所以elif后也可以不接else,代码也是完整的。
if嵌套

if嵌套的逻辑,就是因为有些条件下又分出多个条件,大条件下包含着几个小条件。
input()函数
当我们在终端输入选择时,下一步的程序就激活了,可以接着往下运行,input()函数就像一个加油站,加满油(输入信息)就可以接着往下跑了。
input()函数输入的是一个等待回复的信息,虽然这个信息也会被输出,但是跟print()函数不同,’请输入同班同学的名字:’它在等待一个答案。
input()函数会将括号内的信息完全输出,同时在终端区域它还等待你的回答,一般会有个光标在句尾忽隐忽现,就是在等待你的回复。
如果我们一直不输入信息,它就一直停留在这里,苦苦等待,也不会再有任何反馈。
input()函数就是代码征途上的加油站,在这里必须要停留,而且要加油(回复信息),代码才能一步步往下跑,如果停留在这里不加油,代码运行就会卡在这里。
一旦我们输入信息(加油),计算机就收到了回应,带你走向下一段代码。
input()函数在我们时常接触的网络中随处可见,搜索、输入账号密码、发帖,可以说有输入框就有input()函数的身影,知道它有多重要了吧。

input()函数结果如何赋值
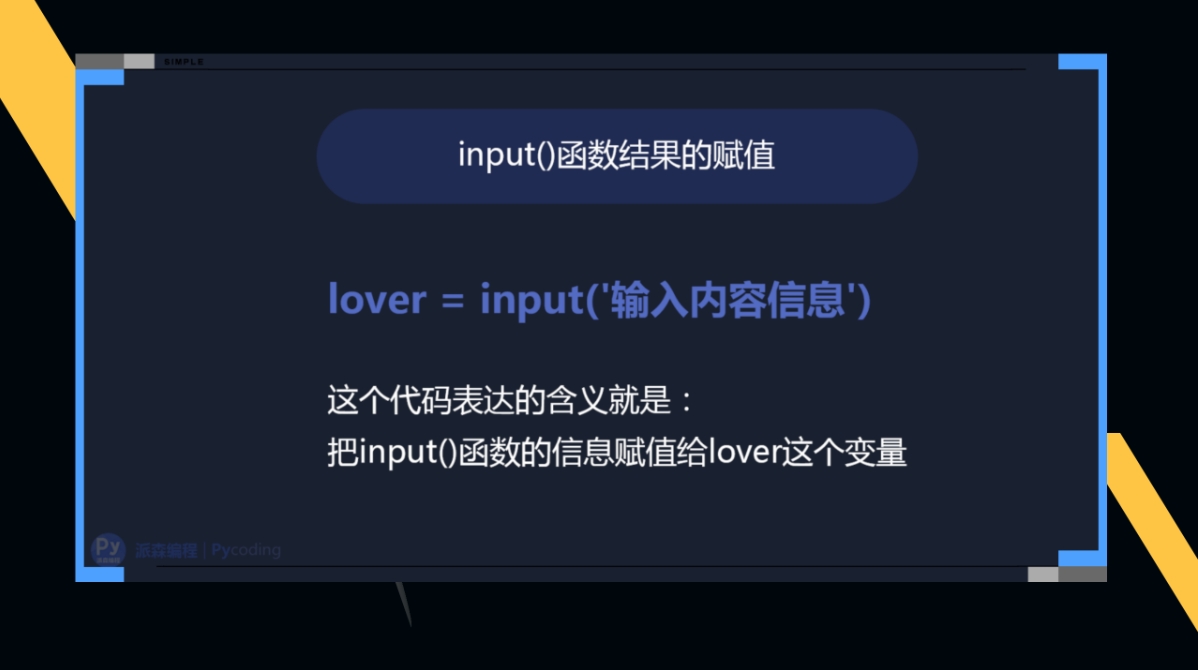
把input()函数收集到的信息保存到一个变量中,这个变量就保存了信息,以后直接打印变量名,就可以得到结果。
划重点,input()函数输入的信息永远是以字符串的数据形式保存着,也就是说,即使输入的是1整数,但保存下来是’1’这个字符串,要切记。
input()函数的数据类型
input()函数输入信息时,不论我们填写的是中文、英文还是整数小数,都会被转换成字符串保存下来,也就是说如果你输入的是整数1,得到的就是字符串’1’,你输入的是字母A,得到的也是字符串’A’。

列表和字典
计算机的常规工作,就是在处理各种数据,搞清楚数据类型的特点,才能实现数据的读取和分析。
如果对数据类型搞不清楚,就无法计算,更谈不上建立数据模型,数据不但对计算机重要,它也是人工智能的基础原料,没有数据也就谈不上人工智能。
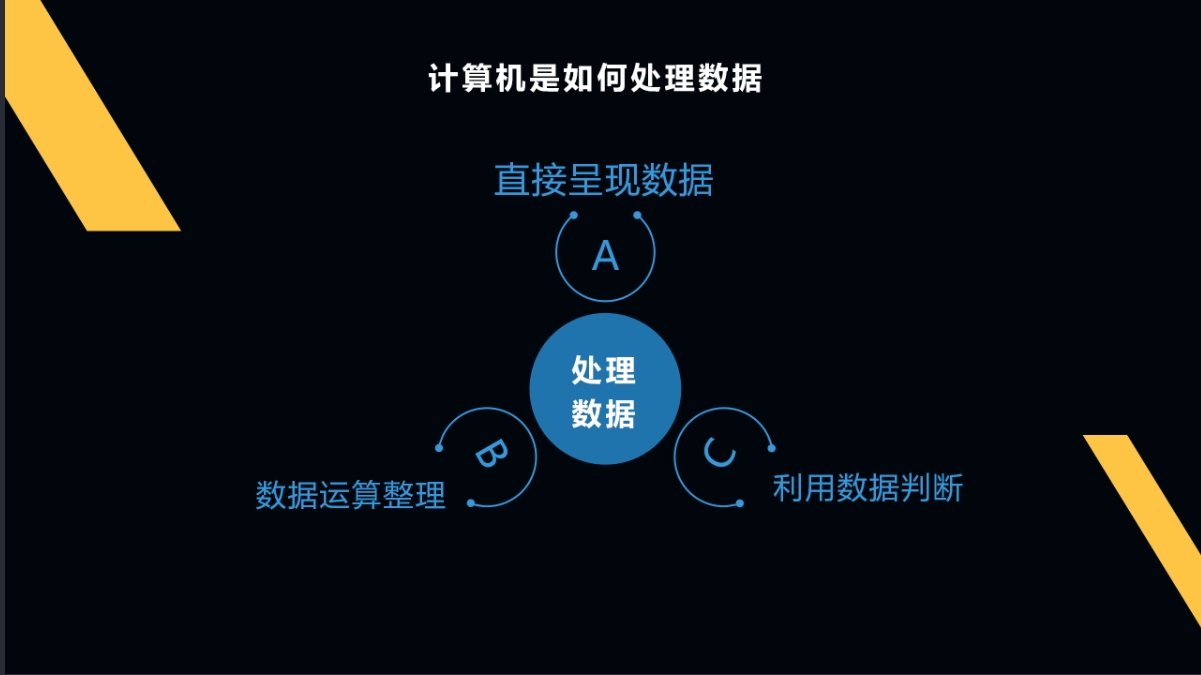
数据的类型会多种多样,但计算机处理数据通常有3种方式:
相比之前学过的“整数、浮点数、字符串”,今天我们接触的数据类型——列表和字典会显得更具包容性,在形式上显得也更高级。
因为不论是整数、浮点数,还是字符串,每次赋值只能保存一条数据。当我们要处理大量的数据时,这种方法就显得效率低下。
这时我们就需要一种可以储存大量数据,并且可以方便计算机进行读取和运算的数据类型——列表和字典。
列表4种操作
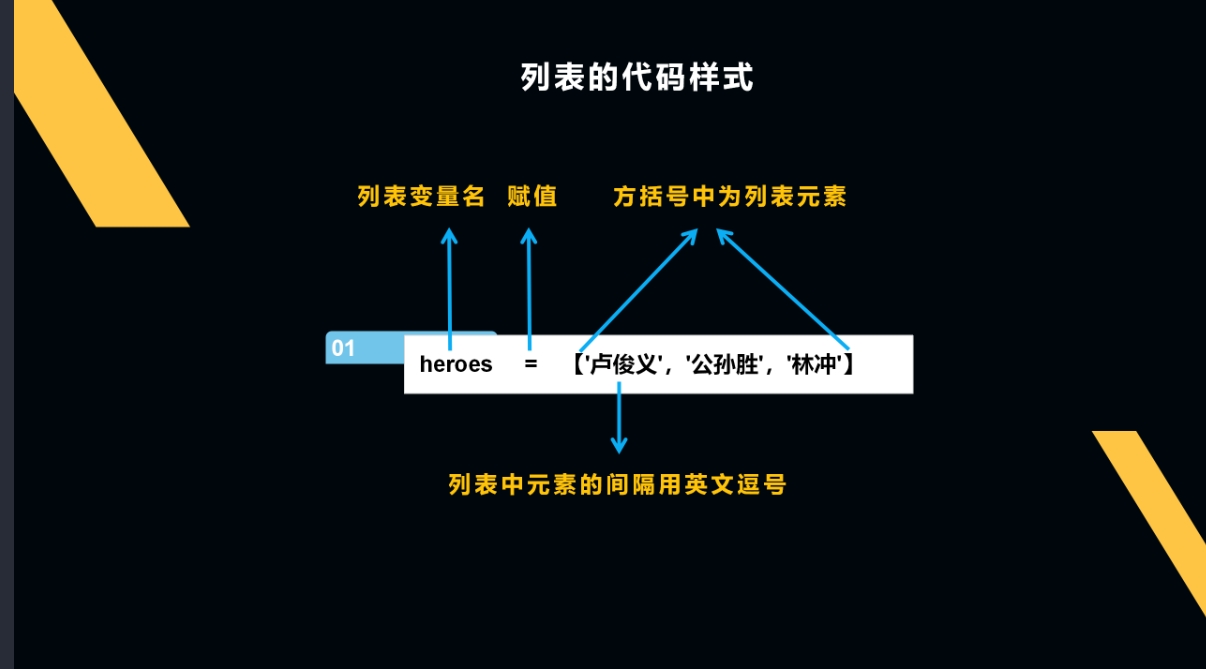
通过heroes变量赋值,我们来认识一下列表的代码格式:
从列表提取单个元素
要提取元素,首先要知道元素的位置,知道位置才能找对元素。在这里有个关键的知识点就是:下标。所谓“下标”,就是编号,就好比超市中的存储柜的编号,通过这个编号就能找到相应的存储空间。
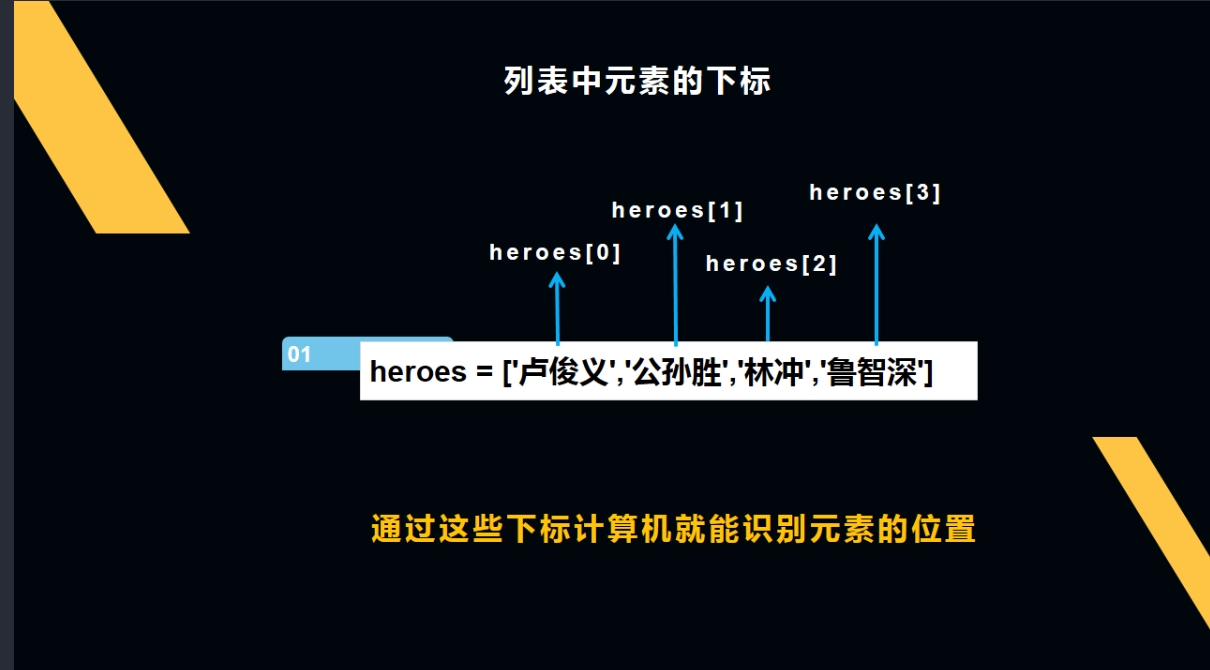
仔细观察上图可以得出几个关键点:1.下标是从0开始的,而不是从1开始;2.列表名后加带下标的方括号,就能取到相应位置的元素。
所以,我们可以通过偏移量来对列表进行索引(可理解为搜索定位),读取我们所需的元素。
从列表提取多个元素
代码中用冒号来截取列表元素的操作叫作切片,切片是指对操作的对象截取其中一部分的操作。字符串、列表都支持切片操作。
切片的规则:选取的区间从”起始”位开始,到”结束”位的前一位结束(不包含结束位本身)。
我们以冒号为参考,得出列表切片口诀:冒号左右为空取全部,冒号左边下标要取,冒号右边下标不取。
增/删列表元素
这就需要用到append()函数给列表增加元素,append的意思是附加,增补。
元素常用删除语句
del语句的基本表达式是 del 列表名[元素下标] ,补全下面的代码,将’人在囧途’从列表中删除,并打印出来。

del语句非常方便,既能删除一个元素,也能一次删除多个元素(原理和切片类似,左取右不取)。
列表这种数据类型还涉及一些操作等待你去探索,我们发现列表保存的数据都是一个维度的,如果我们要保存多维度的数据,列表就无能为力了。
数据类型:字典
我们需要保存的数据往往都不是单个维度的,比如一个人的信息,包括:年龄、性别、身高等。
这类数据用“字典”(dictionary)来存储会更方便,如果用列表,还要建立多个列表,不方便查询。
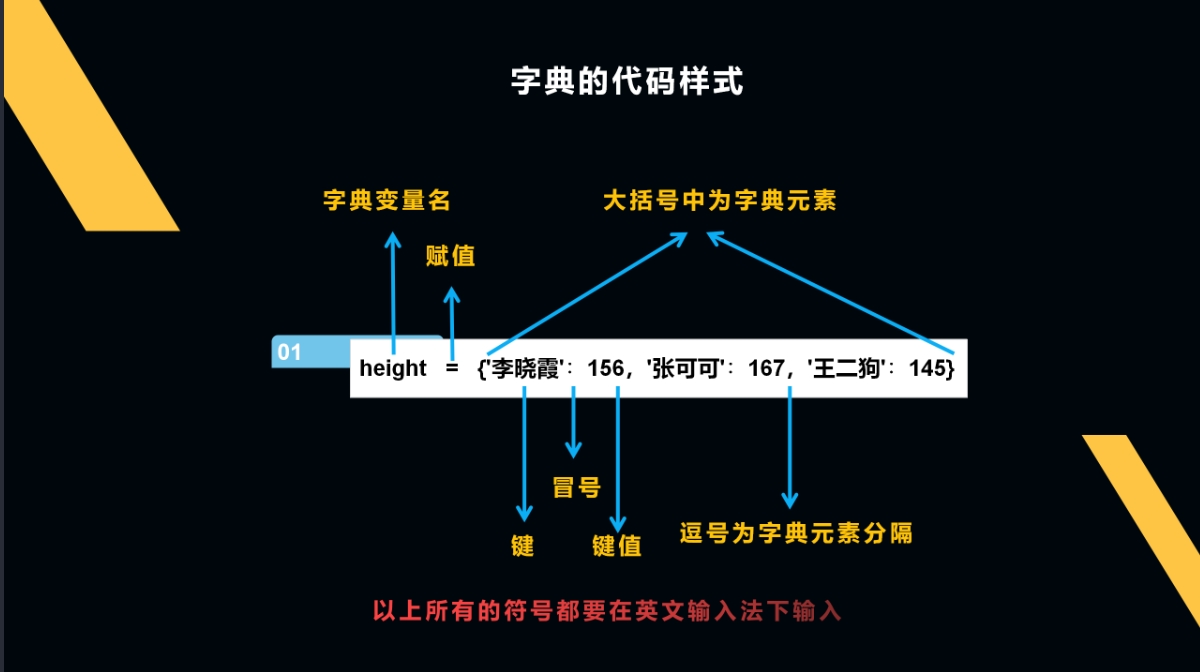
字典和列表有3个地方相同:1.有名称;2.要用=赋值;3.用逗号作为元素间的分隔符。
字典和列表的不同之处:1.列表外层用的是方括号[ ],字典的外层是大括号{ }。
字典的元素是由一个个键值对构成的,用英文冒号连接。
代码实操把李晓霞的身高从字典里打印出来。这就涉及到字典的索引,和列表通过偏移量来索引不同,字典靠的是键。
字典中增加/删除元素
字典中删除元素跟列表一样,都用到del语句。
删除字典里键值对的代码是del语句del 字典名[键],而新增键值对要用到赋值语句字典名[键] = 值。
列表和字典的异同
在python编程中列表和字典都能存储多条数据的数据类型,如果要修改元素,都可用赋值语句来完成。
一个不同点:列表中的元素是有自己明确的“位置”的,所以即使看似相同的元素,只要在列表所处的位置不同,它们就是两个不同的元素。而字典相比起来就显得随和很多,调动顺序也不影响。
列表数据是有序排列,而字典数据是随机排列的。所以两者数据读取方法也不同:列表有序,要用下标定位;字典无序,便通过唯一的键来取值。
列表和字典还有一个相同点就是都支持任意嵌套。除之前学过的数据类型外,列表可嵌套其他列表和字典,字典也可嵌套其他字典和列表。
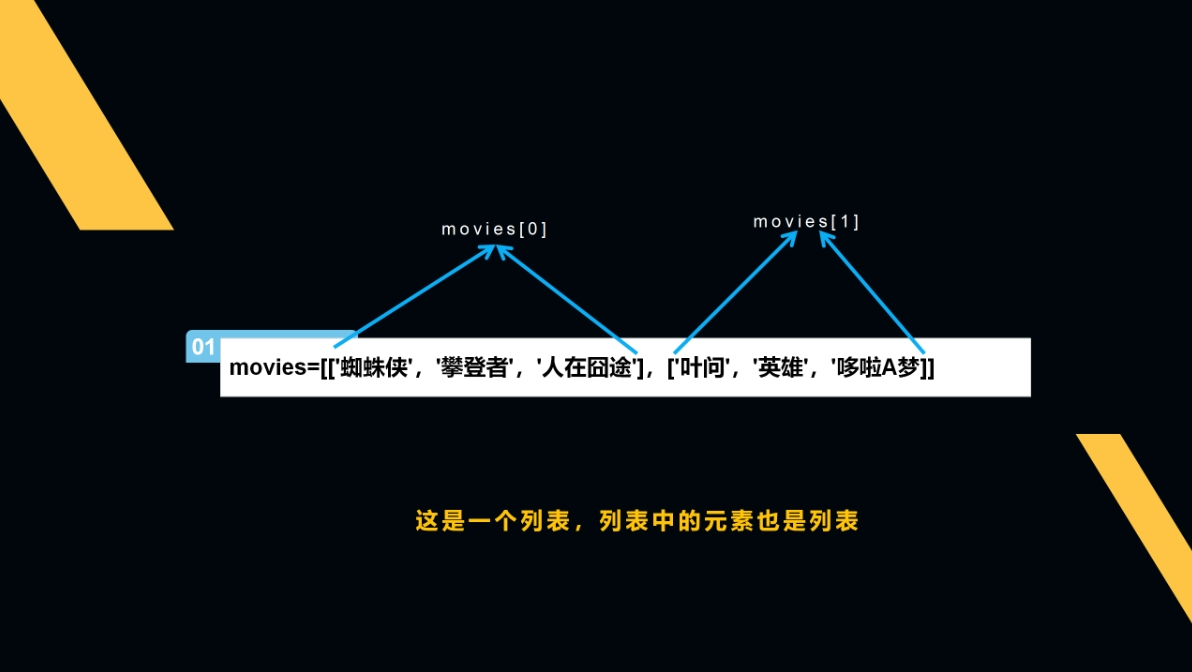
列表嵌套列表
字典嵌套字典
字典嵌套字典和列表嵌套列表也是类似的,只不过列表是以元素下标定位取出,而字典是以键名称。
循环语句——for循环和while循环
先来学习第一种循环的方式:for…in…循环,也可简称为for循环。在Python中for循环可以遍历任何序列的项目,如一个列表或者一个字符串等。
for…in…循环语句
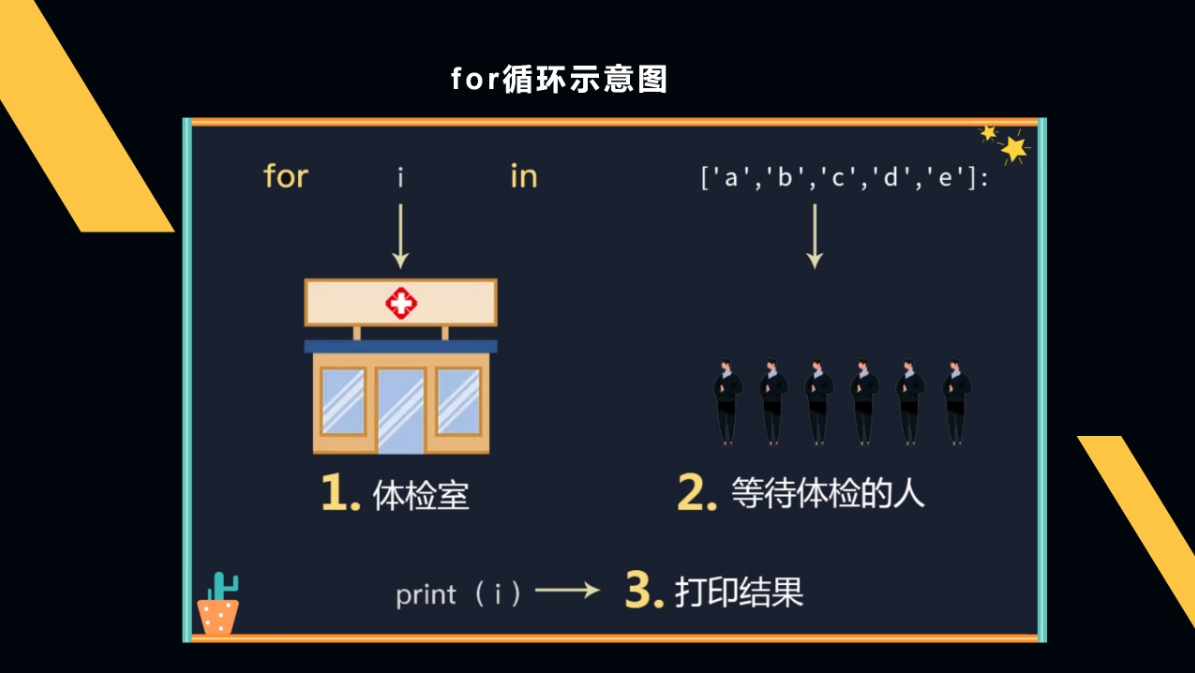
【i】这个“体检室”,每个人都要经过这里,编程语言叫【元素】(item),它也是一个变量。
为什么我总是用i?因为英文是item,所以i是常用名嘛。但其实你给这个房间取什么名字都行。
列表,字典,字符串都可以是“等待体检的人”,而整数和浮点数不可以。
for循环挨个把数据结构(列表、字典、字符串等)里的元素打印出来,在Python中叫做【遍历】。
除了列表,字典,字符串三种数据类型,和for循环常常一起搭配使用的还有range() 函数。
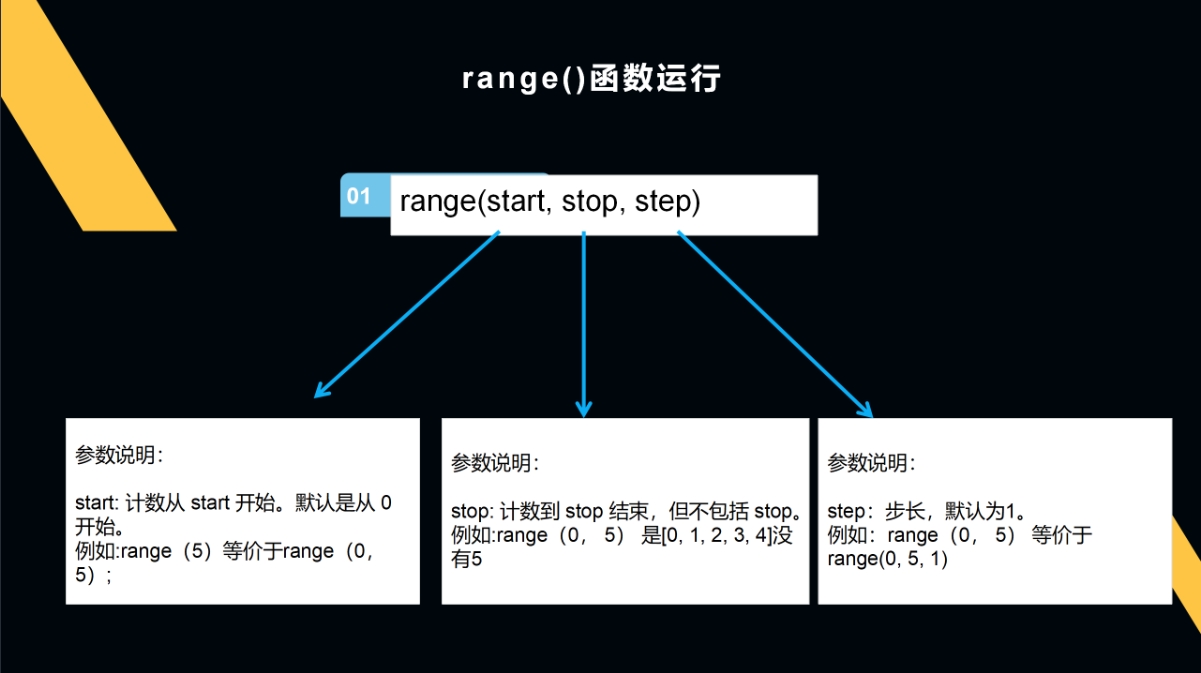
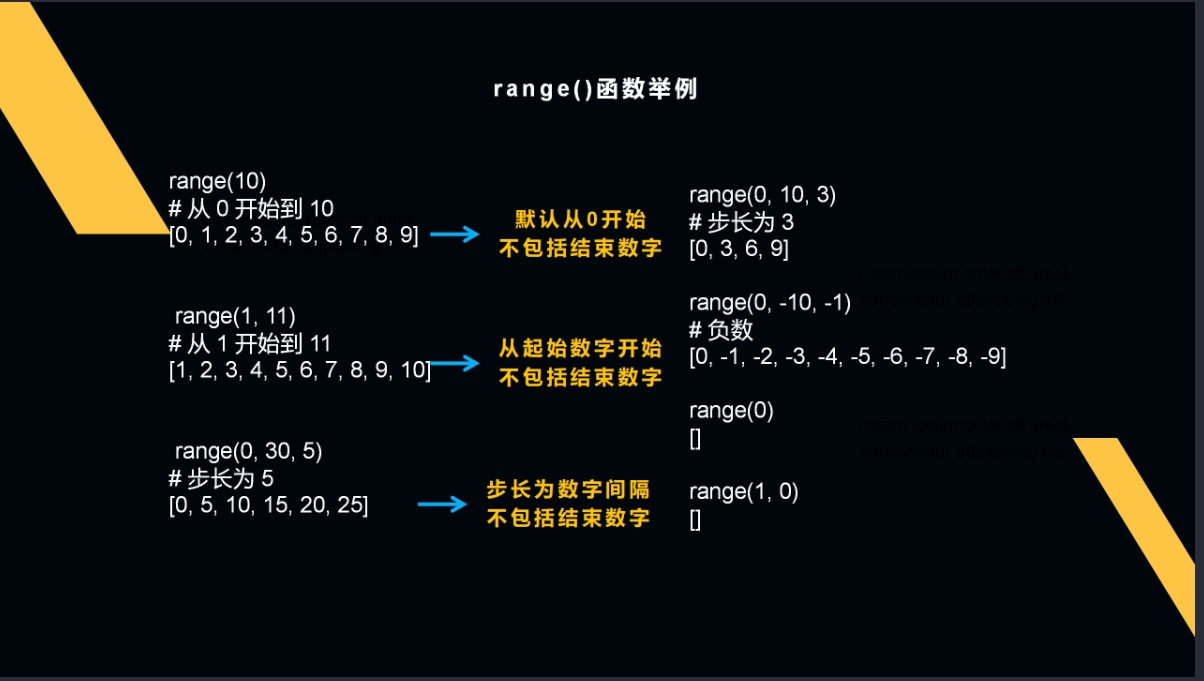
range()函数
range()函数常用的三种表现形态:一种是整数序列,一种是重复打印,还有一种是根据步长取数。
用range()函数取数,当(x)括号中是一个整数时就生成一个从0到x-1的整数序列。
当(x,y)括号中是一个切片数据段时,就生成一个从x到y-1的整数序列(【取头不取尾】)。
如果只是简单地取数,range()函数还不够强大,它还有一个功能就是把一段代码固定重复n次。
range()函数还有一种常见用法就是——步长取数,步长就是数据间的间隔。
for循环:打印结果
for循环第一句代码定义了循环的范围,什么样的人才能走进“体检室”,格式要点是【冒号】,千万不要漏掉,后另起一行缩进(4个空格或者按一次tab键)写命令——打印结果。
打印结果定义了,“等待体检的人”以什么样的方式走出来,最简单就是用print()函数打印出来。
while循环
和for循环语句不同,while语句更直接,只要满足条件,它就会一直运行下面的代码,直到条件不符合。
while循环有2个要点:1.放行条件;2.办事流程。
while循环:满足条件
while语句也要注意代码规范:

while循环:执行任务
while循环,在满足条件的时候,会一轮又一轮地循环执行代码。缩进后的【while子句】才是会被循环执行的“后续任务”。
循环的目的就是为了消灭重复重复性的劳动。
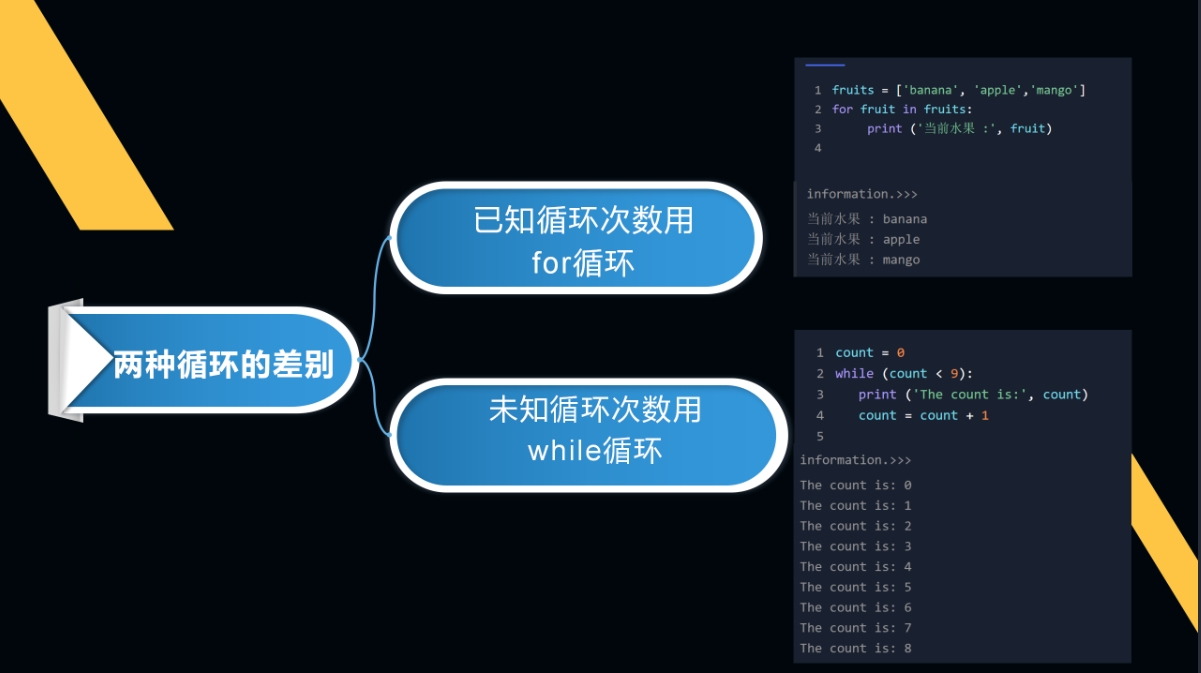
什么时候用for什么时候用while

千万别轻视这两个循环语句,将来在批量处理信息的时候都离不开。
深入的学习循环语句的使用方式:
认识布尔值
计算机有几种不同的方式来使用数据呢?我们之前提到过有三种方式:1.直接使用数据,2.对数据进行计算和加工,3.使用数据进行判断。
关于循环的方式,除了while循环,还有我们之前学过的if…elif…else语句,这个语句中也涉及到【用数据做判断】。当条件判断被满足时才会继续执行任务:
从循环规则上面看,if和while有一个非常明显的区别。if语句:只执行一次;而while语句:只要条件判断为真,就会一直循环执行当前的任务。
那么这个“判断”条件是否被满足的过程,在计算机的世界里是如何进行的呢?
计算机的逻辑判断中只存在两者结果真and假,也就是True(中文意思是“真”)and False(中文意思是“假”),没有中间地带。所以我们将判断真假的过程,称之为【布尔运算】。
因此True和False,被称为【布尔值】。
布尔运算三种方式
将两个数值做比较时的【布尔运算】,会出现以下几种情况:

重点记住前两种==和!=这两个比较特殊的运算符,这两种在一般的条件判断中运用广泛。
在代码中,A == B表示A和B相等;但A = B表示给变量A赋予了一个值B。虽然“=”和“==”外观差别不大,但他们不是“亲戚”,没有关系。
布尔值之间的运算

小口诀:and求同,or求一;and要求两个条件为真,才会输出真;or只要一个条件为真,就可以输出真。